Project Laminar
Beating Schwab Intelligent Portfolios with ease.
On January 1st, 2023, I decided to start building the AO3 Discovery Engine. The motivation for this project was three fold:
This post will summarize the path from the original idea to the release of AO3 Disco v1.0 on the Google Play store and where I plan to go from here.
At the very beginning, I planned to build a web application that would allow people to build collections of works, and then for each collection, they would get suggestions for additional works that fit the "theme" of each collection. We actually got fairly far along in this process before discovering two issues:
These discoveries - in addition with the fact that I was interested in learning mobile development - led me to pivot to building a mobile app. The key feature I was looking for? The ability to "share" a work from your browser to the app and get recommendations - no copy and pasting needed.
Then, upon discovering that the registration fee for submitting an app to Android's Play Store was only \$25 while Apple's App Store was \$99, I decided to start with an Android app.
And that's how AO3 Disco was born.
When building the mobile app, I encountered several false starts. I started by trying to build the app using Jetpack Compose, the latest framework for building mobile apps officially supported by Google. As it turns out, I have no clue how to use Kotlin.
After rapidly going through a bunch of frameworks - Java for Android, Flutter, Xamarin, etc. - and concluding that they were all really hard to use, I finally settled on Ionic/Capacitor, a framework which would allow me to implement most of the app using web technologies and only using native plugins for the tricky stuff.
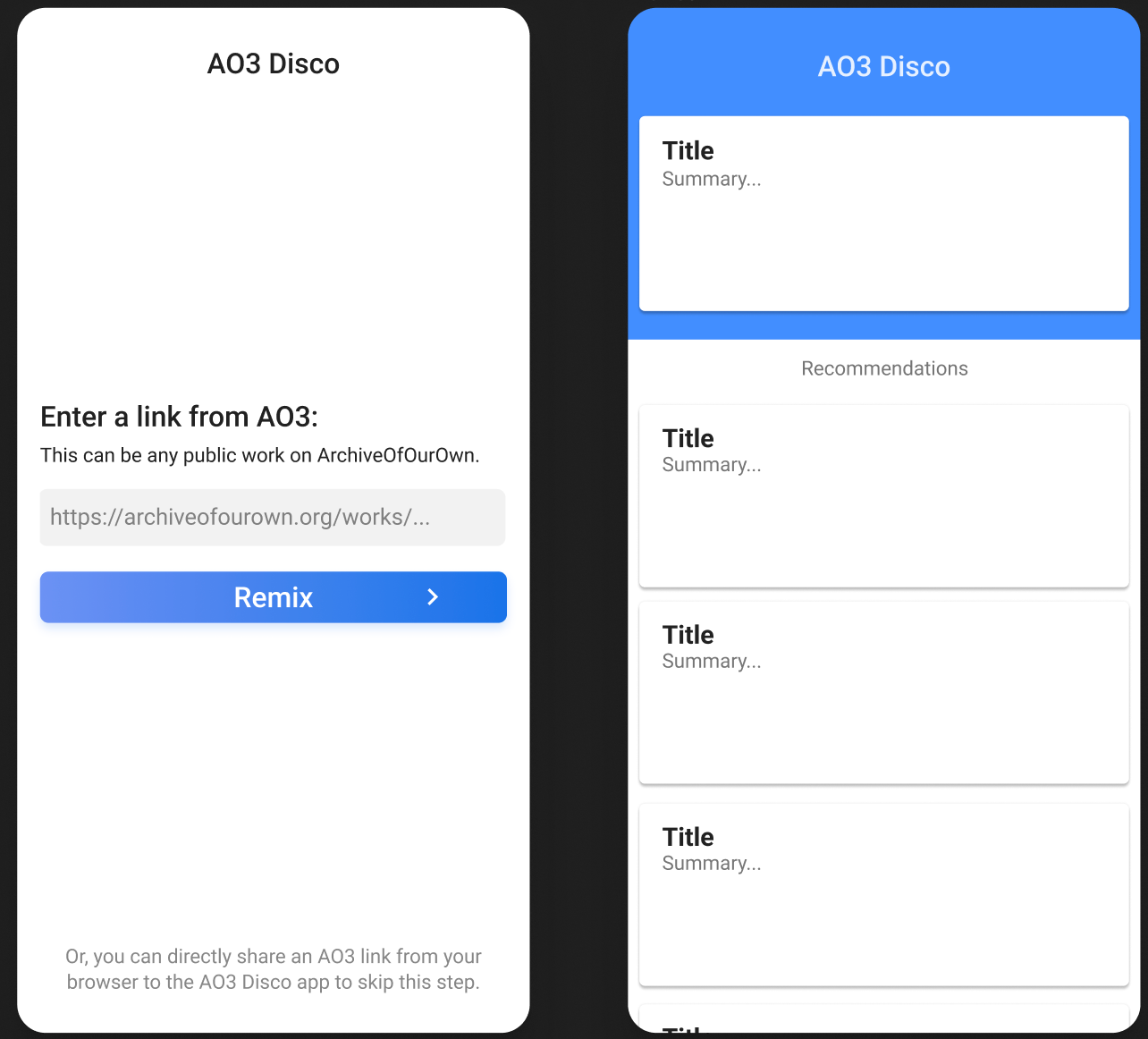
Having finally decided upon a tech stack for the front-end of the app itself, I proceeded to blunder my way through implementing a MVP which provided 2 capabilities: sharing a work from a browser and allowing users to scroll through a deck of recommendations.
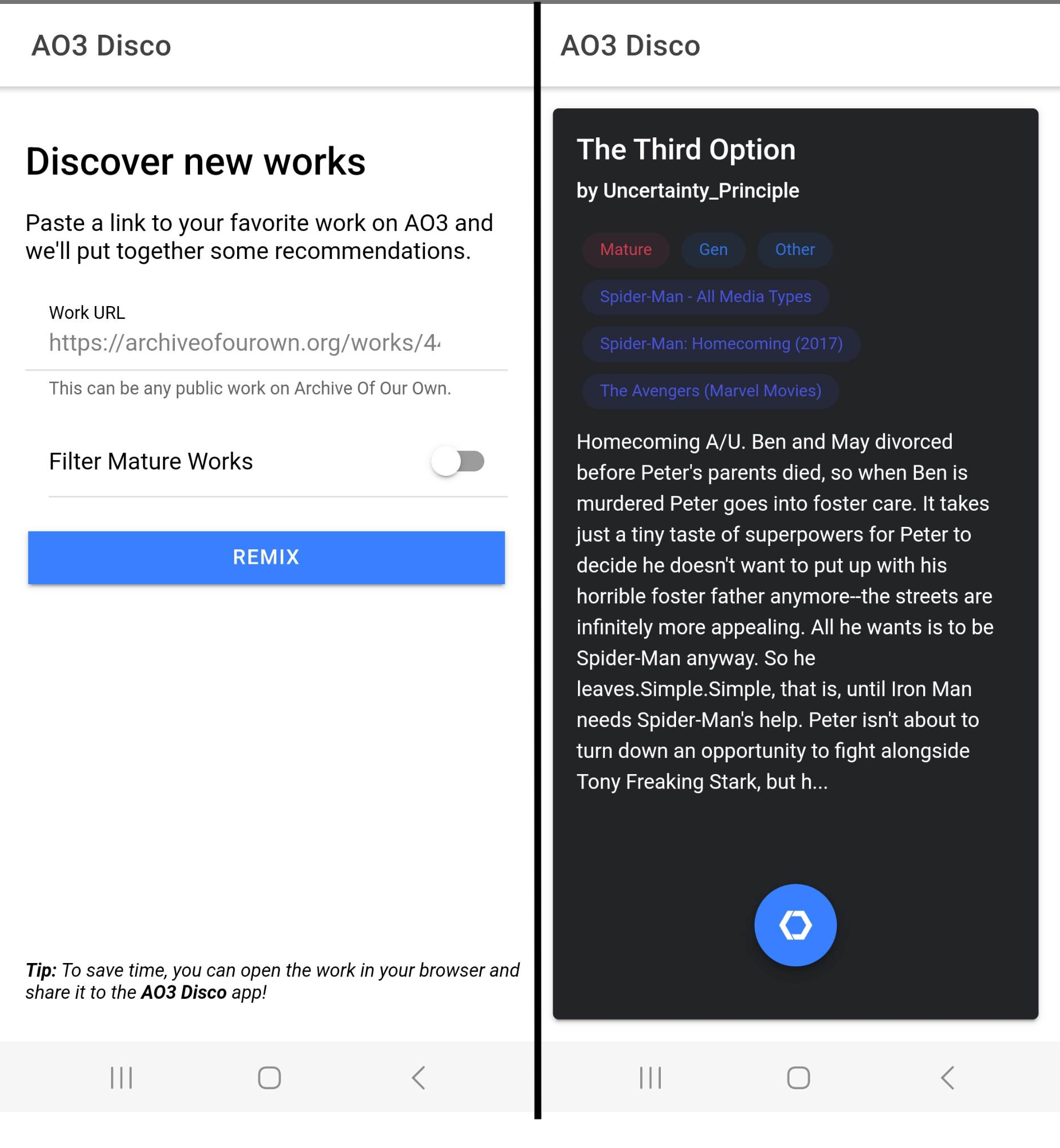
I posted in a relatively smaller subreddit (r/TheCitadel) asking users to give our app a try and received lots of actionable feedback. This led us to v1.0 of the app which added new features such as bookmarks, history, filters, snoozing, and more.
This was released publicly a week later and posted to several subreddits, including r/rational, where I received a lot of awesome technical questions, leading me to draft this post.
Currently, there are two discovery engines available in the app that the users can choose from. Eventually, I hope to be able to combine them into a single optimized engine by adding a second stage model, but as I have not figured out a way to balance the trade-offs yet, it's currently up to the user to choose which experience they prefer:
The benefits of the classic model are clear:
This classic model is also very similar to what many others have tried to do (i.e. when looking for similar systems, I found a desktop app + some Jupyter notebooks that do this exact thing). The drawbacks, however, are fairly significant:
To mask some of these drawbacks, in the current system, when the classic model is unable to come up with any recommendations, we fall back to the freeform model.
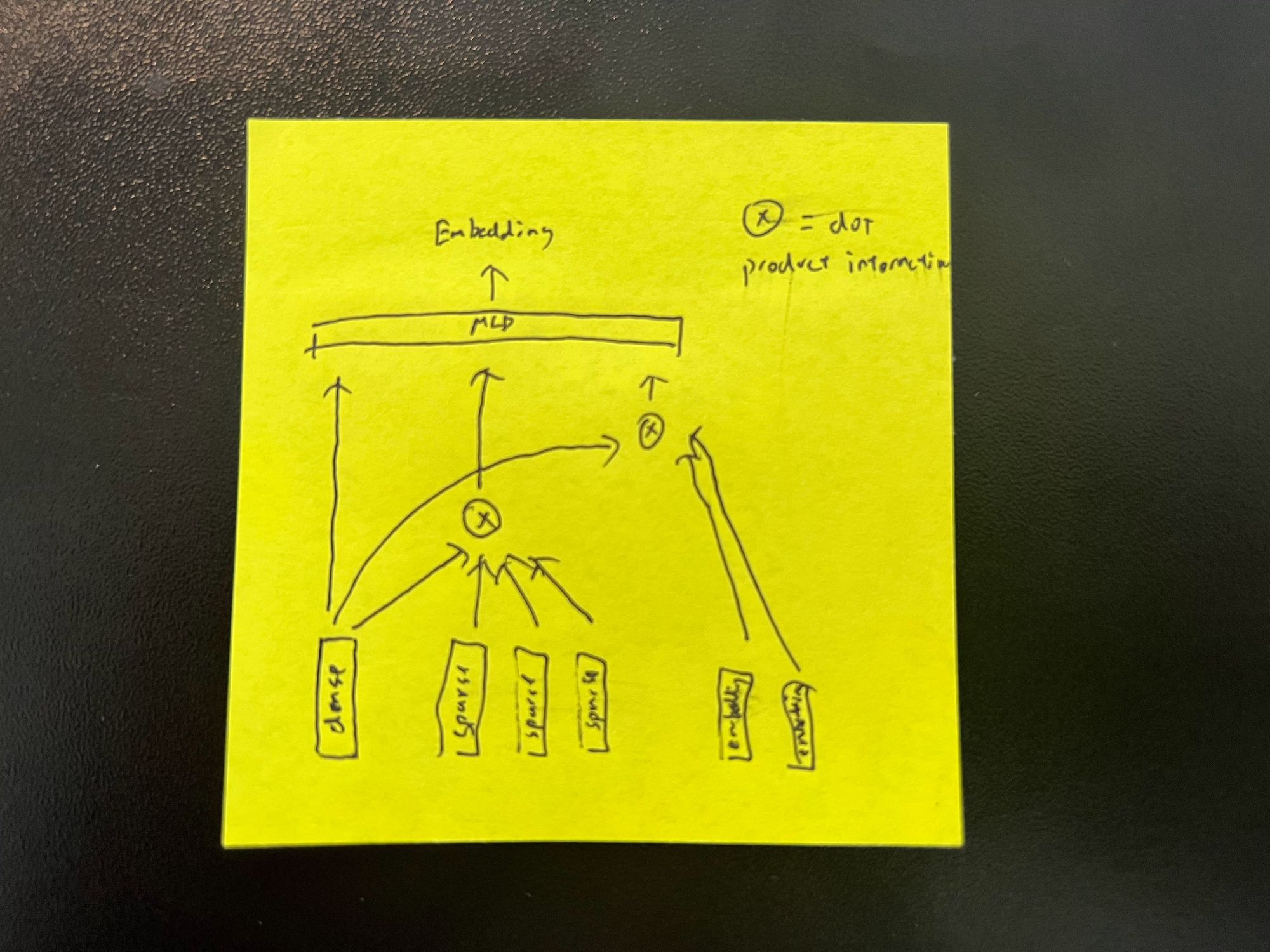
The freeform model is designed to overcome these limitations. Instead of relying on the user-work connections, we use a neural network that analyzes each work independently and generates a vector embedding. Then, to get recommendations, we can efficiently find the nearby vectors using a library such as Spotify's annoy.
There are three classes of features which are passed to the model:
The architecture of the freeform model is designed to combine these three feature types together into a single embedding vector:
This architecture is quite similar to those proposed in works such as [2] [3]. We currently train this model using a modified triplet loss [4] which aims to pull works in the same collection closer together while pushing randomly sampled works that don't belong to the collection further away.
Of course, this approach has drawbacks as well. On several instances - prior to building a robust validation system - I published a model that would spit out random garbage, and debugging it would require dumping the model parameters, inspecting the gradients, and manually checking the embedding vectors.
Furthermore, this is a lot more computationally expensive and greatly increases both the latency and the cost of the servers needed to run AO3 Disco.
First, I have a long list of planned improvements to the existing Android app, ranging from allowing users to export their recommendations to making it possible to filter on custom tags. In addition, I plan to make upgrades to the "freeform" model and improve the quality of recommendations overall.

After all of that though, here are the big new directions that I would like to explore:
[2] https://quoraengineering.quora.com/Unifying-dense-and-sparse-features-for-neural-networks
[3] https://arxiv.org/pdf/1906.00091.pdf
[4] https://towardsdatascience.com/triplet-loss-advanced-intro-49a07b7d8905